SemiNMF-PCA framework for Sparse Data Co-clustering
Allab, Labiod, and Nadif (2016) in CIKM
Research Paper
9 Jan 2024
Co-clustering
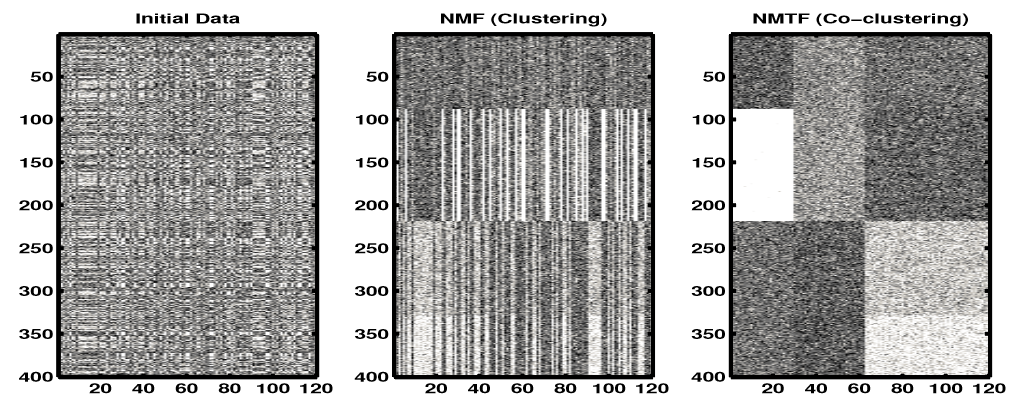
Clustering vs. Co-clustering: Allab, Labiod, and Nadif (2016)
Results
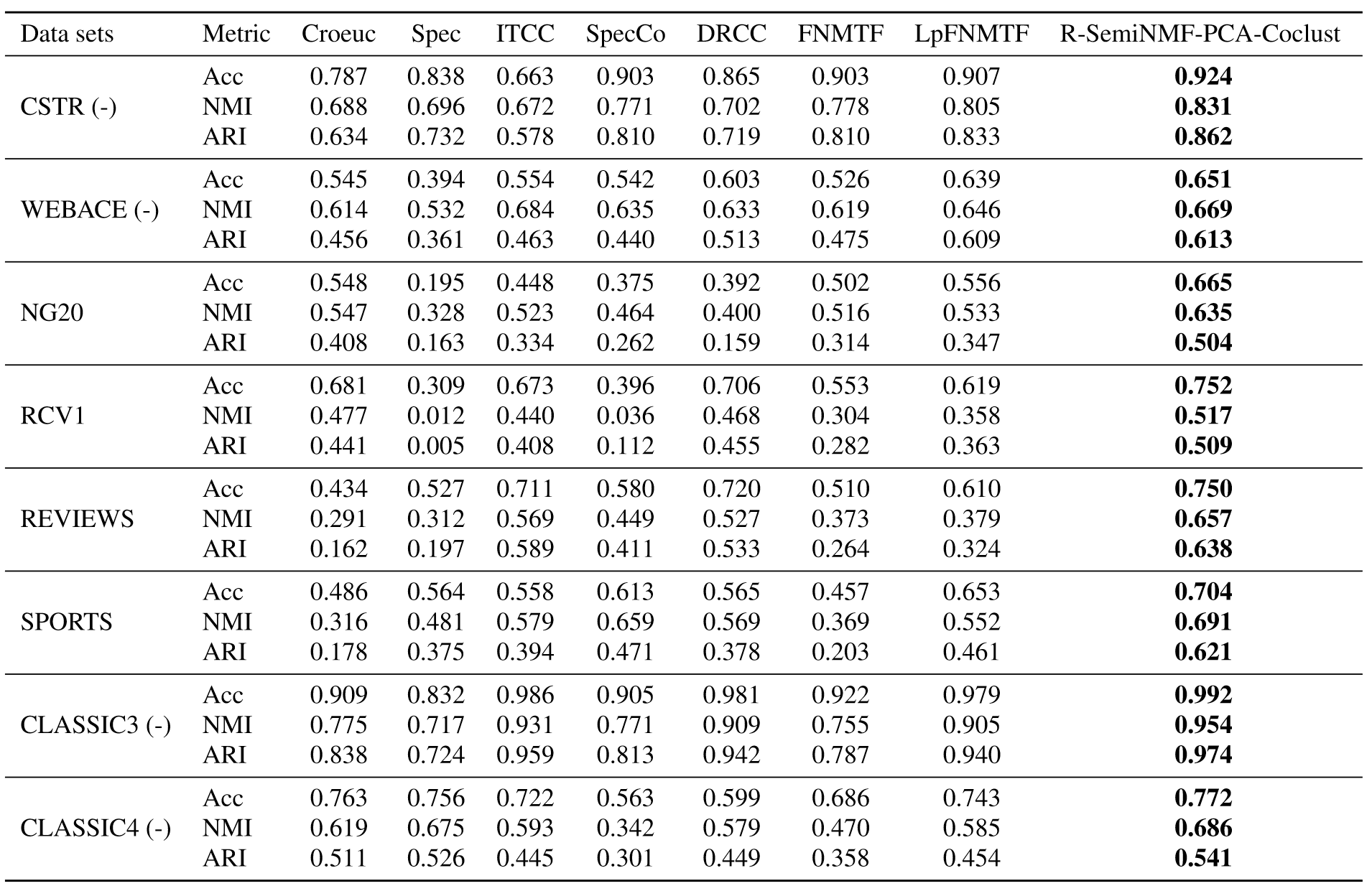
Allab, Labiod, and Nadif (2016)
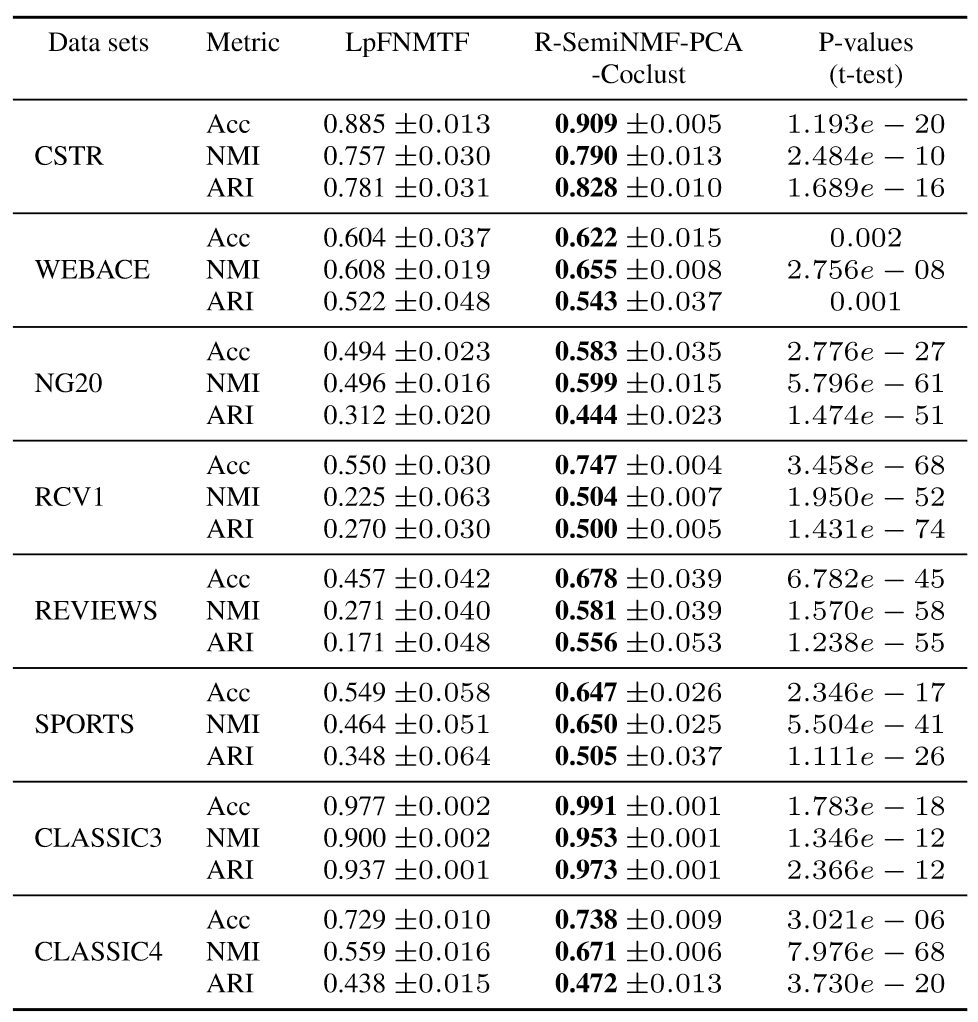
Results: Statistical Tests
- One-way ANOVA & pairwise t-tests
- Show statistically significant performance increase over LpFNMTF
Cluster Visualization

Allab, Labiod, and Nadif (2016)
- The method groups clusters to provide clearer separation between them; there’s less overlap
Regularization parameters
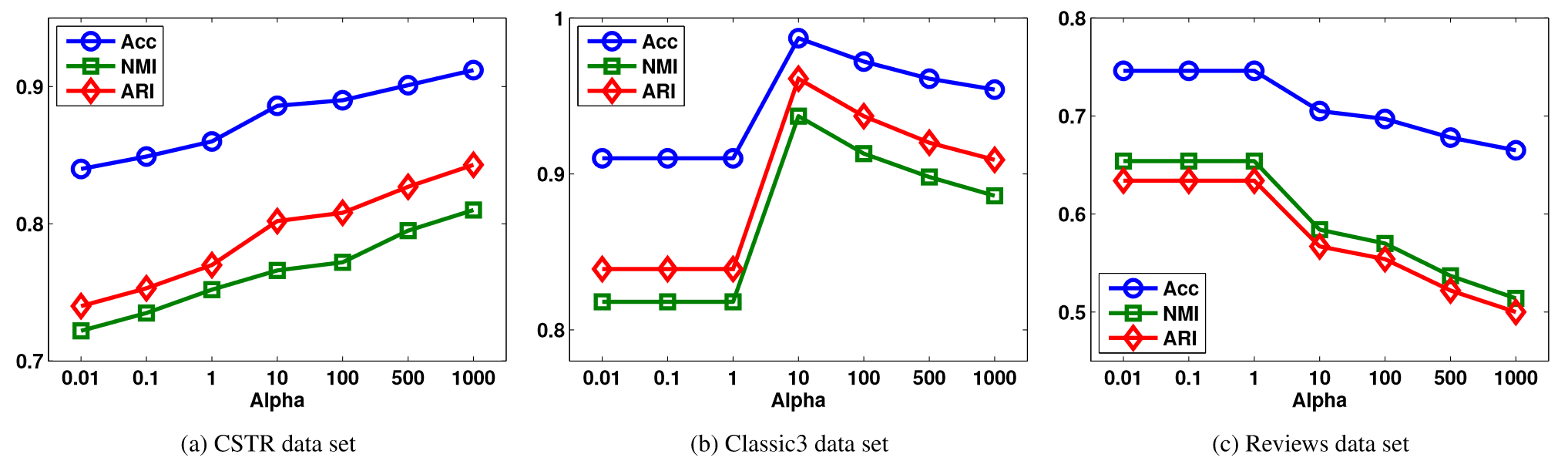
Allab, Labiod, and Nadif (2016)
- CSTR: Performance increases with increase in \(\alpha\)
- Classic3: Optimal at \(\alpha=10\)
- Reviews: Performance decreases with increase in \(\alpha\)
- Choosing optimal parameters for datasets vs. generalization
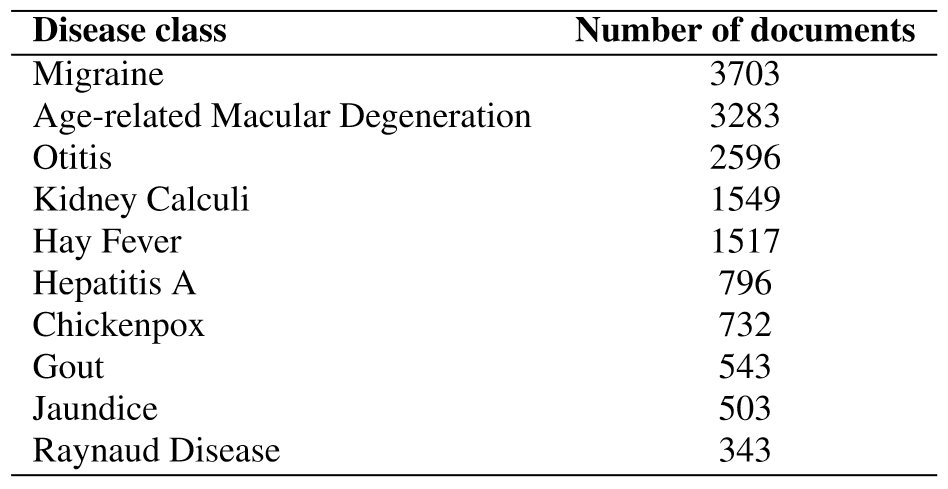
PUBMED10
- Biomedical abstracts categorized by disease
- Divided into
- PUBMED10
- PUBMED6
- PUBMED5
Results

Allab, Labiod, and Nadif (2016)
Dense bands of variables - terms cited in many docs - considered noise.
Results
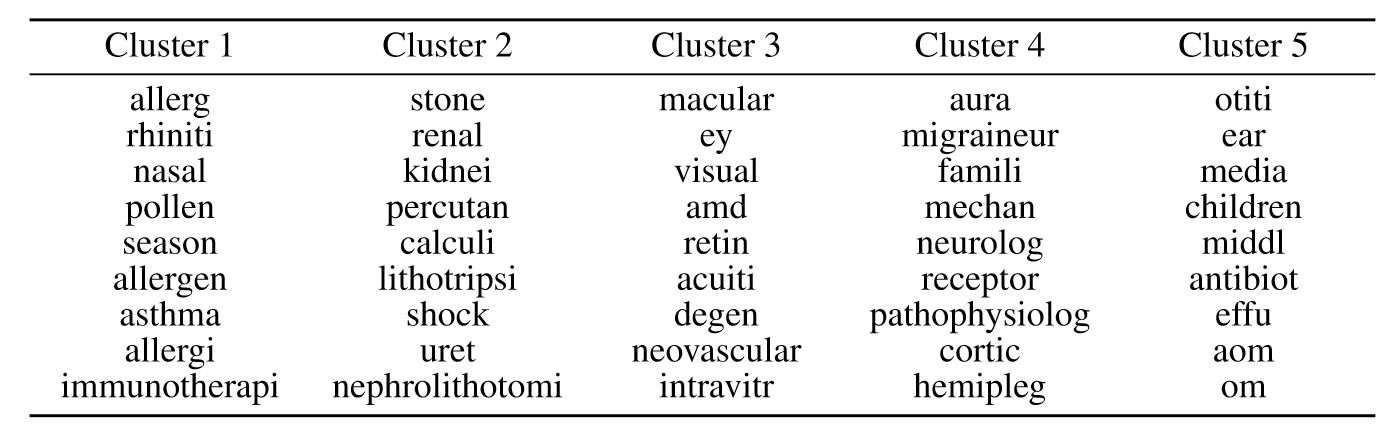
Allab, Labiod, and Nadif (2016)
- Identified semantically coherent column clusters indicative of document clusters - seems to correspond to diseases
- Found common terms between different diseases - showing ability to handle overlap and shared features between clusters